AI Agents Explained: Smarter, Faster, and More Independent Than Ever
- Why Now?
- The Evolution of AI Agents
- Anatomy of an AI Agent
- Designing Agentic AI Systems in Production
- Challenges & Limitations of AI Agents
- Bottom Line
Imagine having a personal assistant who never sleeps, learns on the fly, and can book your flights, summarize your emails, debug your code, and even negotiate deals—without you lifting a finger. That’s not science fiction anymore. Welcome to the world of AI agents.
AI agents are more than just chatbots. They’re autonomous systems powered by large language models (LLMs) that can reason, plan, and take action using a variety of tools. Unlike traditional software that follows fixed rules, AI agents can adapt to new situations, make decisions in real time, and collaborate with other agents to tackle complex tasks.
In this blog, we’ll break down:
- The evolution of AI Agents
- Anatomy of those systems
- Types of AI Agents
- Challenges and limitations you should know
Why Now?
The concept of autonomous agents has been around for decades, but it’s only in the last 2–3 years that they’ve become truly practical. This sudden leap is the result of several converging trends:
- Powerful Language Models: The arrival of GPT-4, Claude, Gemini, and other advanced LLMs has given agents the ability to reason, understand context, and generate human-like responses at scale.
- Tool Integration Frameworks: Frameworks like LangChain, Semantic Kernel, and CrewAI make it easy for agents to use external tools—APIs, search engines, databases, code execution environments—on demand.
- Cheaper & Faster Compute: Cloud providers now offer more affordable, faster GPUs, reducing the barrier to running continuous, high-capacity agent workflows.
- Multi-Agent Coordination: Orchestration platforms allow multiple agents to collaborate on complex tasks, dividing work just like human teams do.
- Explosion of Open-Source Projects: Open-source tools like Auto-GPT, BabyAGI, and CAMEL have lowered the barrier for developers and hobbyists to experiment with autonomous AI.
This combination of brains (LLMs), hands (tools & APIs), and infrastructure (compute & orchestration) has pushed AI agents from research prototypes into usable, real-world systems.
Let’s dive in.
The Evolution of AI Agents
➡️ 1980s–2000s: Rule-Based Systems
Expert systems with if–then–else rules. Narrow but rigid.
Example: ELIZA, early IVR menus.
➡️ 2010–2018: Task-Specific Bots
NLP let bots understand intent. Handy for FAQs & reminders, but still brittle.
Example: Siri, Alexa (early versions).
➡️ 2019–2022: LLM-Powered Agents
GPT-3 brought contextual reasoning & coherent text. Great at conversation, but passive.
Example: ChatGPT in early workflows.
➡️ 2023–Present: Autonomous Agents
Agents now plan tasks, call APIs, execute code, and self-correct.
Examples: Auto-GPT, BabyAGI, LangChain, Semantic Kernel.
➡️ Emerging: Multi-Agent Systems
Teams of agents working like humans — delegating, negotiating, collaborating.
Examples: Experimental distributed dev & research agents.
In short: We’ve gone from brittle, rule-based bots to adaptive, tool-using digital teammates that can coordinate with each other. Each leap has been driven by advances in language understanding, reasoning, and integration with the digital world—and the next leap may be agents that learn and evolve continuously without retraining.
Anatomy of an AI Agent
At their core, AI agents combine intelligence (reasoning and decision-making) with capability (the ability to act in the world). While implementations vary, most modern AI agents share a common set of building blocks:
Here is a diagram showing the backbone of a single AI Agent system
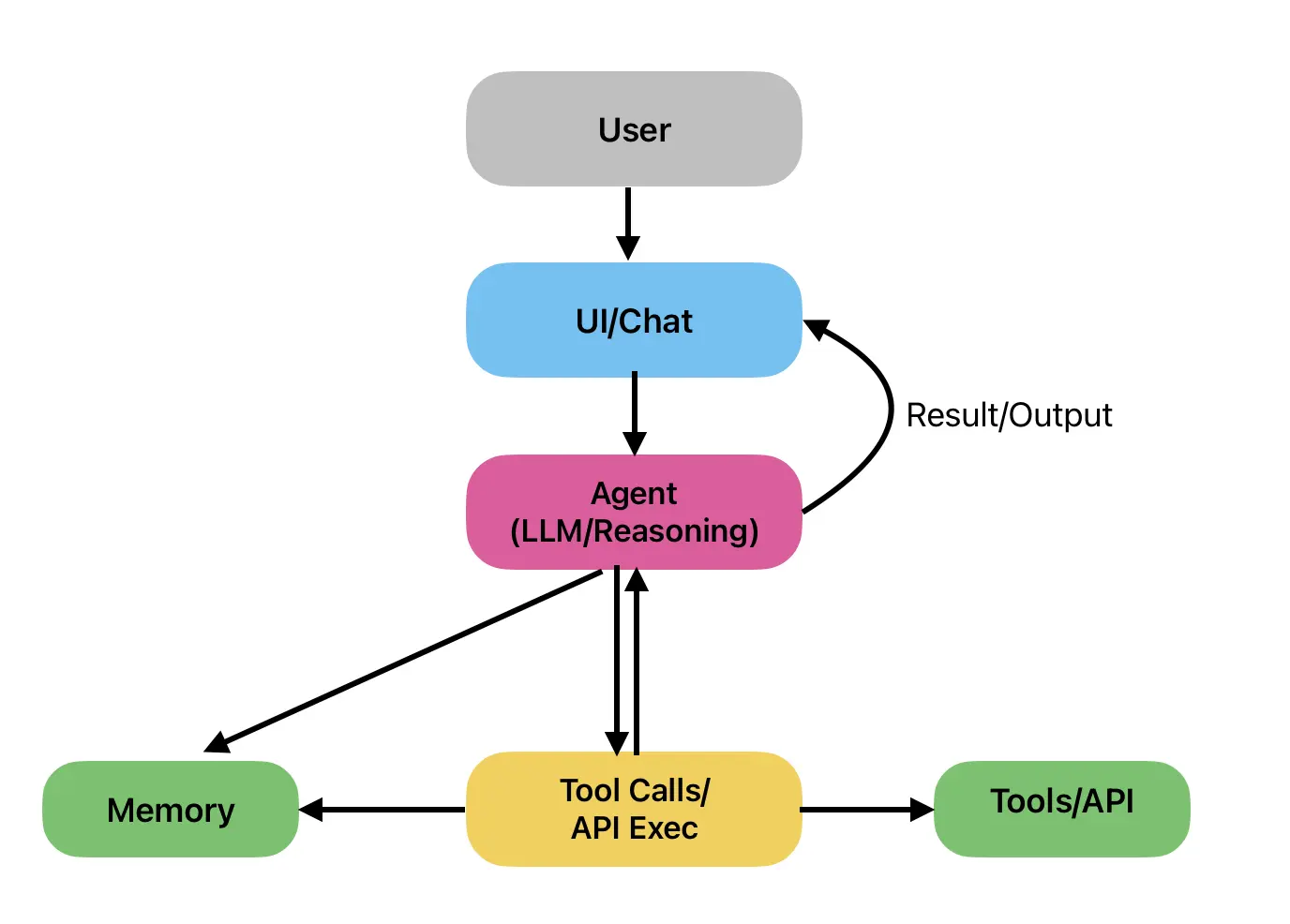
Worker Agent (Brain)
- Purpose: Processes specific user goal/task, breaks them into steps, and decides the best course of action.
- Typical Tech: Large Language Models (LLMs) like GPT-4, Claude, or Gemini.
- Example: Given “Find the latest stock prices and summarize trends,” the reasoning engine decides to:
- Call a financial API.
- Analyze the data.
- Generate a summary in plain English.
Memory
- Short-Term Memory: Keeps track of context within an ongoing interaction (like the current conversation thread).
- Long-Term Memory: Stores past interactions, facts, or preferences for retrieval later.
- Implementation: Vector databases (Pinecone, Weaviate, FAISS) for semantic search.
- Benefit: Enables personalization and continuity across multiple sessions.
Tools & Actions (Hands)
- Purpose: Let the agent interact with the outside world beyond generating text.
- Examples:
- Web search
- API calls
- Code execution
- Database queries
- File creation and editing
- Framework Role: LangChain, Semantic Kernel, and similar frameworks define these tool interfaces.
Orchestrator (Planning and Control)
- Planner: Breaks a complex task into smaller subtasks and sequences them logically.
- Controller: Executes steps, monitors outcomes, and adapts if something goes wrong.
- Example: If a web search fails, the agent retries with a different query or switches data sources.
Feedback Loop (Self-Reflection)
- Purpose: Evaluates outputs and decides whether to refine them before returning results.
- Techniques:
- Chain-of-thought reasoning
- Self-critique prompts
- Peer review in multi-agent setups
- Benefit: Improves reliability and reduces hallucinations.
Interface (Face)
- What Users See: The medium through which humans interact with the agent.
- Forms:
- Chat interfaces
- Voice assistants
- API endpoints
- Embedded widgets in apps
This modular design means developers can swap components—using a different LLM, adding new tools, or expanding memory—without rewriting the entire system.
Using all the above components, we now have a diagram for multiple AI Agents in a system.
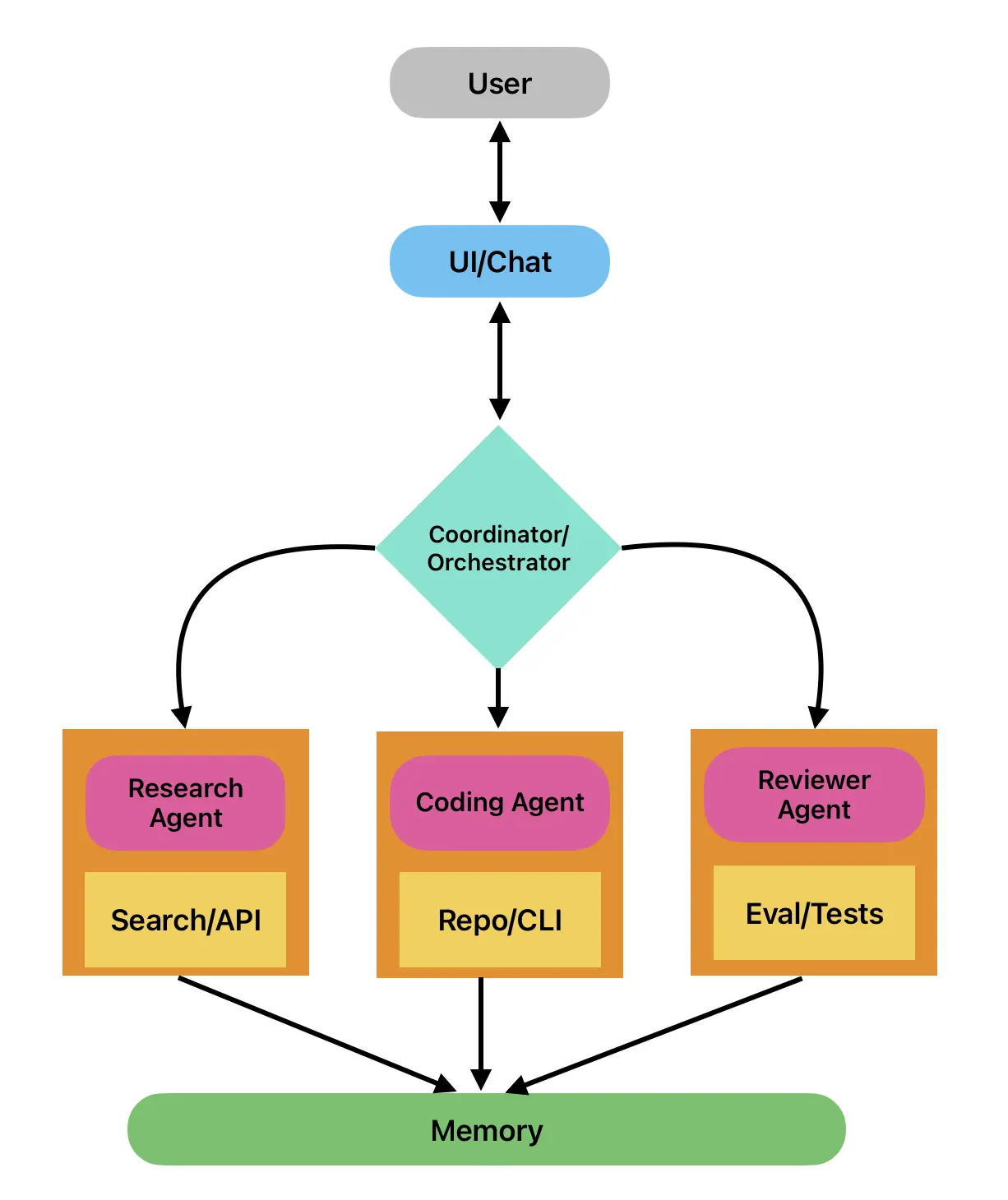
Designing Agentic AI Systems in Production
Prototypes of agentic AI often rely on a notebook + a LangChain-style loop. In production, that breaks down. You need distributed systems design, explicit state handling, monitoring pipelines, and fault-tolerant orchestration.
Orchestration & Control Plane
- Execution Graphs: Instead of
while True: agent.step(), define DAGs or state machines. Tools:- LangGraph for LLM-driven graphs with persistence.
- Temporal.io / Durable Functions for deterministic, replayable workflows.
- Control Plane Responsibilities:
- Step scheduling (event-loop vs. async tasks).
- State checkpointing (Redis, Postgres, S3).
- Backpressure handling (via Kafka partitions or Pub/Sub topics).
- Failure Modes: Detect infinite loops (
max_turns), cascading retries, and stale state locks.
Agent Runtime Environment
- Isolation: Run each agent in its own container/sandbox (Firecracker microVMs or gVisor) to avoid side-effects.
- Concurrency: For CPU-bound agents, use async IO + thread pools; for GPU-bound ones, batch calls through Triton Inference Server.
- Inter-agent Messaging:
- Synchronous: gRPC with deadlines + retries.
- Asynchronous: Kafka topics with schema contracts (Avro/Protobuf).
- State Serialization: Normalize agent state into JSON schema + embeddings; version schema to prevent drift.
Data Plane & Memory Systems
- Short-term Memory: Redis/KeyDB with TTL eviction for transient context.
- Long-term Memory: Vector DB (Weaviate, Milvus, FAISS) with namespace partitioning per agent.
- Cross-Agent Memory: Avoid global memory pools; use scoped “capability stores” → each agent queries only embeddings relevant to its role.
- Caching: Response caching via Cloudflare KV or DynamoDB to cut repeated LLM calls.
Monitoring, Tracing, & Debugging
- Structured Logging: Emit JSON logs with
trace_id,agent_id,session_id,latency_ms,token_count. - Distributed Tracing: OpenTelemetry spans for every LLM call + external API call. Attach vector-db hits as baggage.
- Cost Attribution: Meter GPU/LLM invocations per request; aggregate by user → needed for billing and abuse detection.
- Debug Replay: Persist full trajectories (inputs, model configs, decisions) → enable offline replay & regression testing.
Hardening & Guardrails
- Static Constraints:
- JSON schema validation for outputs.
- Prompt templates with deterministic slots instead of raw free-form text.
- Dynamic Controls:
- Rate-limit agent → external API calls via Envoy filters.
- Kill-switch per agent (e.g., set
enabled=falsein config → propagate via feature flags).
- Security:
- JWT-scoped credentials per agent.
- Never give all agents RW DB access → enforce least privilege.
CI/CD & Evaluation Loops
- Offline Evaluation: Maintain golden test suites of user prompts + expected JSON/action outputs.
- Canary Releases: Route ~1% of traffic to new agent policies; rollback if metrics regress.
- Shadow Mode: Run new policies in parallel → log differences without user exposure.
- Telemetry-driven Improvement: Continuous fine-tuning using production traces (after redaction & differential privacy).
Challenges & Limitations of AI Agents
AI agents may be powerful, but they’re far from perfect. Understanding their limitations helps set realistic expectations and design safer, more reliable systems.
| Challenge | Why It Happens | Impact | Mitigation |
|---|---|---|---|
| Hallucinations & Inaccuracy | LLMs generate words probabilistically, not based on truth. | Wrong answers → misinformation, wasted effort. | Fact-checking layers, Retrieval-Augmented Generation (RAG). |
| Reliability in Long Tasks | Tool errors, inconsistent reasoning, goal drift. | Agents stall, loop, or fail mid-process. | Watchdog processes, timeouts, checkpointing. |
| Security & Privacy Risks | Weak permissions, poor prompt design, unsafe inputs. | Sensitive data leaks, unsafe actions. | Strict tool access, input/output sanitization, avoid externalizing sensitive data. |
| Cost & Resource Usage | Long contexts, excessive LLM/API calls, multi-agent chatter. | High bills, inefficient compute usage. | Prompt optimization, caching, usage monitoring & budgeting. |
| Evaluation & Benchmarking | Success often subjective, creative, or multi-dimensional. | Hard to measure quality or progress. | Define clear KPIs, human-in-the-loop evaluation. |
| Ethical & Alignment Concerns | Misaligned goals, vague prompts, loopholes. | Unintended or harmful behaviors. | Safety filters, guardrails, limit autonomy in high-stakes areas. |
In multi-agentic AI systems, it is essential for knowing the right steps where “human in the loop” is required, having robust security/authentication mechanisms to ensure that the agents do not carry out destructive processes and the orchestration ensuring that the correct agent is invoked.
Bottom Line
While AI agents can unlock huge productivity gains, they require careful design, monitoring, and control mechanisms to be both safe and effective. Treat them as powerful assistants—not infallible decision-makers.
The upcoming article (soon to be linked here) will discuss about how Microsoft products adopt and encourage building Agentic AI systems, along with other open source tools.